1. Intro
When you run your program inside Docker, you probably sometimes notice that it takes a long time to stop. You probably even found out that this is because docker stop first sends SIGTERM to the process inside the container, and after a timeout of 10 seconds, it sends SIGKILL.
At this point, you probably followed instructions in the documentation by installing an init system like tini or by declaring a handler for the SIGTERM signal in your program.
I also did that, but for some reason, I kept wondering “Why?”. Why do you have to declare a handler or use the init system? My simple Python script terminates fine with the SIGTERM signal when I run it outside the container.
By searching the Internet some more, I found out that processes with PID 1 are unique in Linux. One (1) is exactly the number of the process that the program starts with inside the container. This program and the PID 1 itself are usually called the init process. The Internet told me that the init process ignores SIGTERM if it does not have a handler for it. But I could not find anywhere, answers to these questions:
- How does the init process ignore signals?
- Why Docker still could terminate it by sending a
SIGKILLsignal? - Why I can’t terminate the init process by sending a
SIGKILLsignal with the commandsudo kill -s SIGKILL 1?
I guess this is why they call it open source so that you can open the source and find out for yourself.
2. Understanding how Linux protects processes with PID 1
When the Linux kernel boots it starts one process in userland called init, which will always get PID 1. The job of this init process is to:
- Start other processes
- Be the ancestor (direct or indirect) of all processes
- Adopt orphaned processes
- Terminate all processes on shutdown
By looking at the source code of the Linux kernel here is a TLDR of how the kernel sends signals to PID 1:
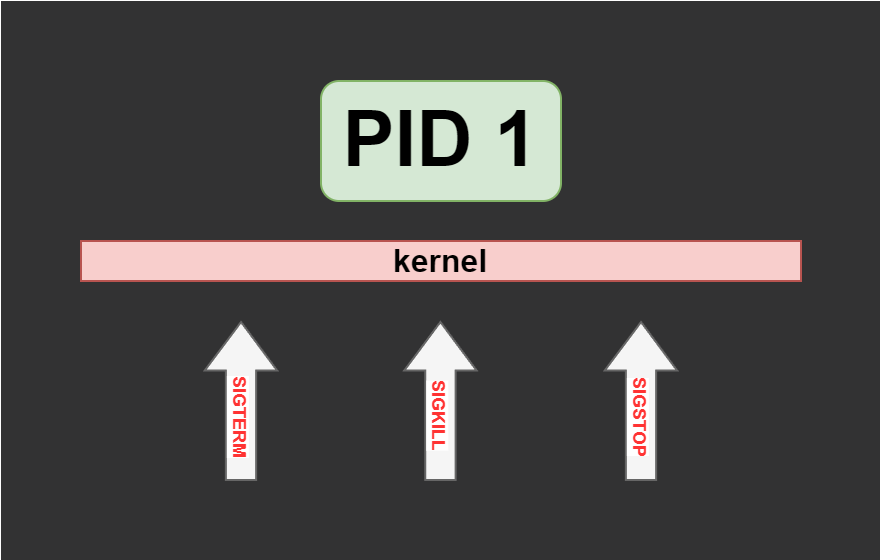
- The init process will not receive any signal unless it explicitly creates a handler for this signal. For example, if you send
SIGTERMto PID 1 process, that didn’t create a handler for this signal, the OS will not send this signal and never terminate the process by default. So this isn’t the case that PID 1 processes ignore signals, it’s that they never receive them in the first place. - The init process will never receive
SIGKILLorSIGSTOPunless it comes from the ancestor namespace. This means that commandsudo kill -s SIGKILL 1didn’t work only because it came from the namespace of the init process itself. Docker can kill it because it sendsSIGKILLfrom the parent namespace.
2.1. Looking under the hood
This is the section where I just describe what happens in the code, and it can be skipped.
At the time of research, the latest stable version of Linux is 6.1, so we will examine the source code of this version.
- Linux starts the init process in
/init/main.cin the rest_init function. - We are interested in line 694 which passes the
kernel_initfunction (which starts the init process) as an argument to the function user_mode_thread from/kernel/fork.cthat starts a process in user mode. user_mode_threadin line 2747 invokes the kernel_clone function.kernel_clonein line 2671 invokes the copy_process function.copy_processis a big function, but in line 2443 it sets theSIGNAL_UNKILLABLEflag for the process that passes theis_child_reapercheck.- is_child_reaper is a function in
include/linux/pid.hthat checks if the process has PID 1 in its own namespace.
Now that PID 1 has the SIGNAL_UNKILLABLE flag, let’s see how signals behave when this flag is set. All functions are contained in one file /kernel/signal.c.
- We start with the send_signal_locked function. It sets the bool
forcevariable. We’ll note that in lines 1247-1251, it setsforceto true if the signal coming from the ancestor namespace. Then it calls the__send_signal_lockedfunction. - __send_signal_locked function in line 1090 will not send the signal to the process if the
prepare_signalfunction returns false. - prepare_signal function in line 970 will return false if the
sig_ignoredfunction will return true. - sig_ignored will return true if the
sig_task_ignoredfunction will return true. - sig_task_ignored function in lines 89-91 will return true if three conditions are met:
unlikely(t->signal->flags & SIGNAL_UNKILLABLE)- if process has theSIGNAL_UNKILLABLEflag set.handler == SIG_DFL- if the handler for a signal is the default handler, meaning the process didn’t register a handler.!(force && sig_kernel_only(sig))- if this expression is falseforcevariable set to falsesig_kernel_only(sig)signal should be notSIGKILLorSIGSTOP- So there are multiple outcomes:
- The signal is not
SIGKILLorSIGSTOP, so this checksig_kernel_only(sig)will return false, so theforcevariable is irrelevant. Since the whole expression will be false. - If the signal is
SIGKILLorSIGSTOP, thenforceis relevant. If it is set to true, meaning that the signal coming from the ancestor namespace, the whole expression will be true and the signal will be sent. If it is false, meaning that the signal coming from the current namespace, the whole expression will be false and the signal will be ignored.
- The signal is not
3. How that relates to Docker
Docker runs processes in namespaces, and the first process created gets PID 1 in its own namespace. PID 1 is special in Linux. When the command docker stop is run, it will send SIGTERM to the PID 1 inside the container. So if the process doesn’t have a handler for SIGTERM, it will not receive it. Docker will wait for 10 seconds and then send SIGKILL. Since that signal will be coming from the ancestor namespace, it will be sent to PID 1 inside the container, and it will be “violently” killed.
And even if the process handles SIGTERM, it could spawn children. The parent process should propagate SIGTERM to its children. So the process with PID 1 inside the container should take the role of the init process on top of its core functions.
Not every container should have some kind of init process. You could handle SIGTERM (or you don’t mind your process of being killed with SIGKILL) and don’t spawn any children. But you probably would want some kind of init process. For that, for example, you can use tini and use -g argument with it to propagate SIGTERM to all processes inside the container.